
Un approccio “learn by doing” al machine learning con Python
1. Machine Learning con Python: introduzione
Il miglior modo di capire qualcosa è studiare la teoria, e poi applicarla al caso pratico. Ho deciso quindi di addentrarmi nel mondo del Machine Learning usando il mio linguaggio di programmazione preferito, Python.
Per meglio dare seguito alle mie letture, ho messo mano alla console e ho sviluppato un semplice algoritmo di classificazione con la libreria SK Learn. Lo scopo di quest’articolo è quindi condividere il mio percorso e la mia esperienza piuttosto che fornire un contributo tecnico-specifico alla causa.

Ovviamente per una comprensione esaustiva delle metodologie che stanno dietro il Machine Learning occorrerebbe partire dai concetti base di algebra lineare, statistica, teoria delle probabilità, calcolo differenziale, studio di funzione, calcolo vettoriale, per poi passare alla programmazione, reti neurali, database, ecc.
Ma per questo c’è chi ha già scritto dei libri al riguardo e lascio il compito a chi avrà voglia di approfondire (la mia picklist: The Hundred-Page Machine Learning Book, Python Data Science HandBook, Quora e Medium).
2. Perché Python?
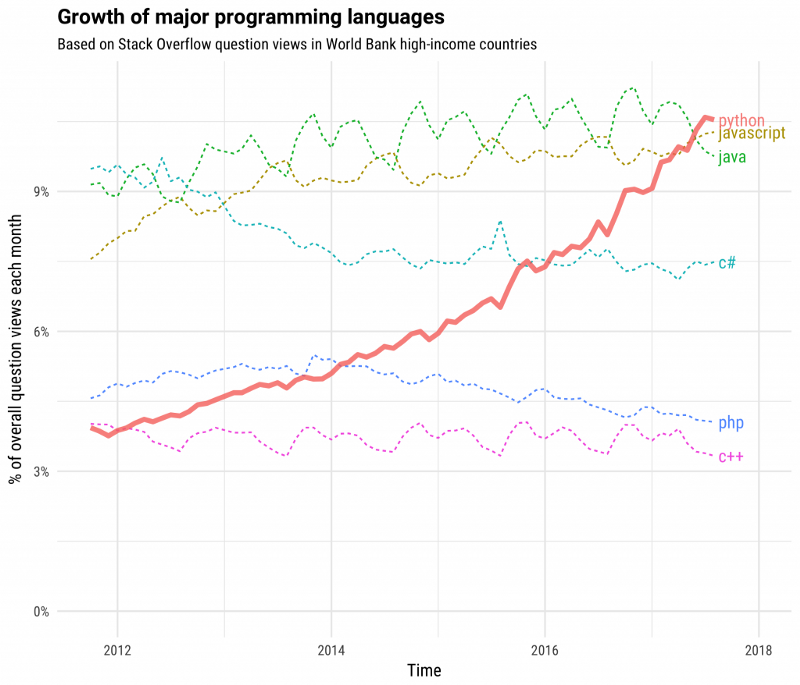
L’utilizzo di Python ha avuto una crescita esponenziale nell’ultimo decennio, il ché significa intanto una community viva e attiva, e quindi un sacco di persone che hanno affrontato e risolto i tuoi stessi problemi prima di te (scopri di più su Stack Overflow — The Incredible Growth of Python).
Inoltre Python offre una gamma vastissima di librerie che consentono di gestire funzioni complesse con un semplice import, rendendo quindi immediato ed agevole analizzare set di dati complessi rendendo la sintassi del codice snella (scopri di più su Udacity — Why Python is the most popular language used for Machine Learning).
In ultimo, perché è un linguaggio di programmazione comprensibile anche senza avere delle basi accademiche (scopri cosa ho imparato in un summer bootcamp su Python — Learning Python the hard way).
3. Machine Learning for dummies
Cosa intendiamo intanto quando parliamo di machine learning? Il termine è ormai quasi di uso corrente, e lo dobbiamo a Arthur Lee Samuel (1901–1990), pioniere nel campo dell’intelligenza artificiale, in particolare applicata ai videogame (ancora una volta gaming e innovazione vanno di pari passo).
Il buon Samuel crea infatti un celebre gioco di dama per IBM, dove grazie ad un algoritmo auto-apprendente, l’opponente virtuale è in grado di imparare giocando contro gli umani e memorizzare strategie di gioco diventando sempre più abile.
In italiano tradotto con “apprendimento automatico”, il machine learning esplora studio e costruzione di algoritmi che possano riconoscere pattern in insieme di dati e fare quindi predizioni in modo induttivo, utilizzando metodi statistici per migliorare progressivamente la qualità dell’output .
Si definisce apprendente un algoritmo la cui performance misurata migliori con l’esperienza:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.[Tom Mitchell, “Machine Learning”, Cap. I]
In via generale, quando ci è utile ricorrere ad algoritmi di apprendimento automatico?
- Quando vogliamo capire a che categoria appartenga un determinato valore di input: questa foto raffigura un cane raggomitolato o una brioche? (Classificazione)
- Quando vogliamo tentare di prevedere il valore futuro di un dato di input noto il suo valore pregresso. Ad esempio prevedere il valore del mercato immobiliare nota la sua serie storica (Regressione)
- Quando vogliamo raggruppare dei dati che presentano caratteristiche simili tra loro: voglio suddividere gli alunni di una scuola in insiemi omogenei tra loro per determinate caratteristiche (Clusterizzazione)
Le tipologie di apprendimento automatico
A seconda dell’approccio utilizzato, il machine learning può essere a sua volta classificato in sottocategorie, che anzi sono utili per capirne le diverse applicazioni pratiche:
- Supervised Learning: in questa categoria l’algoritmo riceve in input dei set di dati opportunamente classificati e la rispettiva indicazione dell’output per ciascun dataset, così che esso possa derivarne la funzione sottostante e usarla per risolvere altri problemi analoghi. Il caso classico è il filtro anti-spam, dove educhiamo l’algoritmo fornendo set di email classificati come spam e come non-spam.
- Unsupervised Learning: in questo caso al sistema vengono forniti set di dati in input, senza però alcuna indicazione a riguardo dell’output o delle loro proprietà. Sarà il sistema che classificherà questi dati in base alla loro similarità. Un esempio tipico avviene creando cluster di consumatori aventi caratteristiche affini tra loro magari non immediatamente individuabili.
- Semi-Supervised Learning: come dice la parola stessa, è un mix dei due approcci.
- Reinforced Learning: approccio molto interessante, usato abbondantemente per programmare le intelligenze artificiali dei videogame. Non c’è un vero e proprio set di dati ma ci sono diverse situazioni che scaturiscono in un premio o in una punizione per il computer; raccogliendo i dati, esso affina l’algoritmo per aumentarne l’output di volta in volta (per comprendere facilmente questo caso, pensiamo all’intelligenza artificiale dietro ad un picchia-duro, dove i colpi a segno sono i premi ed i colpi incassati sono le punizioni. Una prima reazione di apprendimento potrebbe essere probabilmente usare la parata quando l’avversario tenta un colpo).
Hadouken!!
4. Iniziamo!
Obiettivo: vogliamo che il nostro algoritmo sia in grado di capire se una stringa di testo abbia valenza positiva o negativa.
Forse l’approccio con le stringhe complica un poco la comprensione dell’aspetto analitico ma semplifica a mio parere quello del criterio di selezione. Risolveremo questo problema con un duplice approccio:
- Sfruttando le funzioni importabili nel data science kit SKLearn, una raccolta di tool dedicati proprio al data mining e machine learning.
scikit-learn: machine learning in Python – scikit-learn 0.20.2 documentation - Al solo fine di contro-verifica empirica, utilizzando if statement. Quest’approccio semplicistico è inserito solo ai fini di questo esempio e non vuole sostituirsi ad un approccio strutturato al ML. Per altro è per ovvi motivi non replicabile su dataset di grandi dimensioni o con una minima complessità.
Iniziamo a scrivere codice
Per prima cosa, apriamo il nostro IDE ed importiamo le librerie di SKLearn che ci servono:
from sklearn import tree from sklearn.feature_extraction.text import CountVectorizer
Questi comandi ci permettono di importare un albero decisionale, dove ogni nodo rappresenta una variabile e consente di arrivare per passaggi successivi alla loro classificazione. Un decisional tree è davvero così semplice, per lo meno nel suo funzionamento logico:

Una panoramica dei principali algoritmi di classificazione
Non pensiamo però che l’albero decisionale sia l’unico strumento per affrontare la classificazione del nostro dato in un problem di machine learning. Vediamo sinteticamente i principali:
- Naive Bayes: si rifà al teorema di Bayes e mira a stimare la probabilità di un evento sulla base delle sue precedenti esperienze ed ipotesi di dipendenza. Il termine naive, ingenuo, deriva dal fatto che il modello presuppone tutte le funzionalità nel set di dati siano ugualmente importanti e indipendenti, cosa che raramente si verifica nel mondo reale. Ci sono tanti casi di studio validi per approfondire ma volendone sponsorizzare uno in italiano, rimando a questo dell’ottimo Code Q&A.
- SVM (Support Vector Machine): il concetto di base del SVM è quello di costruire, nell’insieme dei dati a disposizione (immaginiamo distribuiti su un piano cartesiano), un piano separatore che divida i campioni tra loro in categorie quanto più omogenee preservando la maggior distanza possibile. Anche qui, per approfondire rimando alla tesi di Nicola Piovesan che illustra in modo approfondito e comprensibile il caso specifico.
- KNN (K-Nearest Neighbors): come dice il nome stesso, quest’algoritmo di classificazione si basa sulle caratteristiche degli elementi più prossimi a quello del cluster o oggetto considerato, utilizzando set di dati opportunamente etichettati come appartenenti ad una classe (ossia il nostro training set). La spiega ulteriore in italiano stavolta da Quora.
- Random Forest: se mettiamo assieme tanti alberi otterremo una foresta, giusto? E in estrema semplificazione una foresta casuale è proprio un classificatore composto da molti alberi di decisione dove ciascuna variabile è inserita nel modello in modo casuale. La classificazione avviene confrontando poi l’insieme dei nodi così formati. Per approfondire rimando a questo video.
Probabilmente l’albero decisionale non è quindi tra gli strumenti più avanzati che ci siano per risolvere problemi computazionali complessi, ma ha il vantaggio di essere molto comprensibile e di poter essere analizzato anche graficamente. Inoltre ben si adatta al nostro dataset semplice e povero di dati.
Proseguiamo con lo sviluppo del nostro algoritmo
L’altra funzione che importiamo invece è CountVectorizer, che ci consente di creare un vettore che rappresenta la frequenze delle parole in ogni stringa, particolarmente utile per analizzare grandi mole di dati. Per approfondire la vasta teoria dietro la vettorializzazione rimando qui.
Forniamo ora il nostro dataset. Questo approccio è un esempio di apprendimento supervisionato in quanto da un insieme di coppie di classificazione nota, vogliamo dedurre una regola che consenta al nostro algoritmo di assegnare un valore ad un nuovo elemento di input.
Il nostro dataset è composto da due training set ed un test set per verificare la bontà dell’addestramento:
- OK_txt — un insieme di stringhe sicuramente positive
- NOK_txt — un insieme di stringhe sicuramente negative
- TST_txt — un insieme di stringhe variabili di controllo che permettono di verificare l’output del nostro modello
OK_txt = ["ti voglio bene", "ti amo molto", "mi piace tanto", "molto bello"] NOK_txt = ["ti odio", "ti odiamo", "non mi capisce", "non lo sopporto"] TST_txt = ["ti odio molto", "noi ci amiamo", "non mi capisce", "è molto bello"]
Andiamo adesso a assegnare una label positiva e negativa alle singole componenti dei due dataset noti e salviamoli in una variabile vettore.
training_txt = OK_txt + NOK_txt training_labels = ["positive"] * len(OK_txt) + ["negative"] * len(NOK_txt) vectorizer = CountVectorizer() vectorizer.fit(training_txt)
Dopodiché costruiamo l’albero decisionale che, tenendo conto della classificazione di tali variabili, sia in grado di esaminare ogni componente-vettore della nostra stringa di test e assegnare esso un valore positivo o negativo.
training_vectors = vectorizer.transform(training_txt) testing_vectors = vectorizer.transform(TST_txt) classifier = tree.DecisionTreeClassifier() classifier.fit(training_vectors, training_labels) predictions= classifier.predict(testing_vectors) print(predictions)
L’output sul nostro dataset di test (che riporto commentato per semplicità di visualizzazione) sarà il seguente:
#TST_txt = ["ti odio molto", "noi ci amiamo", "non mi capisce", "è molto bello"] ['negative', 'positive', 'negative', 'positive']
Analisi dell’output ottenuto
Vediamo subito quindi come la classificazione risulti corretta; modificando i singoli componenti dell’array TST_txt otteniamo risultati diversi, ma come facilmente intuibile visto la pochezza del nostro campione di controllo, usciamo facilmente dal range significativo e l’algoritmo non è in grado di comprendere il nuovo testo immesso.
Si intuisce quindi come, a fronte di un algoritmo tutto sommato semplice, importanza capitale la rivesta un adeguato training del modello, fornendo data di qualità e in grado di coprire casistiche reali.
Immaginiamo ad esempio la difficoltà per un modello del genere di analizzare frasi sarcastiche o dal senso semantico opposto a quello letterale (es. “sei proprio bravo!” usato per indicare in realtà una mancanza).
Possiamo anche poi stampare il nostro albero decisionale ed andarlo ad esaminare da vicino con un semplice tool online, WebGraphiviz.
Inseriamo questa stringa e andiamo nel folder del nostro IDE per cercare il file tree.dot che è stato appena creato.
tree.export_graphviz(classifier, out_file="tree.dot",feature_names=vectorizer.get_feature_names(),)
Con un bel copy-paste del contenuto del medesimo su WebGraphiviz, otteniamo questa rappresentazione che pur nella sua brutale semplicità ci fornisce una traccia che esemplifica il ragionamento fatto dal nostro algoritmo.

5. Test!
Supponiamo a questo punto di voler verificare la bontà di quanto fatto fino qui sfruttando le capacità offerte dalla libreria SKLearn. Siccome siamo in presenza di un dataset minimale, possiamo creare un semplice if statement che esegua lo stesso compito. Vediamo se i due approcci ritorneranno quindi lo stesso risultato:
def manual_classify (text):
if "odio" in text:
return "negative"
if "non" in text:
return "negative"
return "positive"
predictions = []
for text in TST_txt:
prediction = manual_classify(text)
predictions.append(prediction)
print(predictions)
Cosa abbiamo fatto?
Abbiamo detto al nostro algoritmo di controllare se la nostra stringa contiene il termine “odio”, e se trova il termine, è sicuramente negativa.
Altrimenti, prosegue nell’analisi e se trova “non”, ancora è negativa.
In tutti gli altri casi, la sentenza è positiva.
Peccato che come intuibile questo funzioni per questo set di dati fittizio, in quanto in un insieme di dati adeguatamente vasto, l’approccio con if statement non risulterà gestibile, e neppure accurato.
In ogni caso, se ora eseguiamo il comando, sempre sul nostro dataset di test che riporto ancora per comodità, otterremo questo risultato:
#TST_txt = ["ti odio molto", "noi ci amiamo", "non mi capisce", "è molto bello"] ['negative', 'positive', 'negative', 'positive']
Intuiamo subito che se da una parte questo test manuale ci aiuta molto a capire il funzionamento dell’algoritmo, dall’altra rimane un mero esercizio non replicabile su un insieme di dati reale.
6. Machine Learning con Python nel mondo reale – ML IRL
Abbiamo terminato il nostro semplice compitino, ma abbiamo appena scheggiato la scorza di quella che è la metodologia sottostante lo sviluppo di un’applicazione di machine learning.
Generalizzazione: capiamo bene che per quanto vasto sia il dataset che forniamo in pasto al nostro algoritmo, mai potremmo fornire training set (OK_txt) e (NOK_txt) così vasti da racchiudere tutte le sintassi positive e negative possibili. Ecco perché una qualità fondante dell’algoritmo di apprendimento automatico è la capacità di generalizzare, ossia simulare un ragionamento induttivo elaborando correttamente dati del tutto nuovi utilizzando l’esperienza maturata su casi pregressi. Questo si ottiene fornendo un adeguato training set al modello, dal quale sia possibile estrapolare un congruo numero di pattern. Eventuali casi dubbi andrebbero a loro volta classificati anche manualmente istruendo quindi il modello di volta in volta.
Overfitting & Underfitting: il nostro dataset però si presta anche intuitivamente ad un caso di overfitting in quanto l’algoritmo potrebbe interpretare la presenza della locuzione “non” come attributo a valenza negativa. In realtà posso formulare frasi positive e negative anche usando l’avverbio “non” in ciascuna di esse. Il modello sta quindi cercando una relazione di causa-effetto logica che in realtà non sussiste, ed il problema è nel set di dati che abbiamo fornito, dove si evidenzia un pattern che porta ad una conclusione non corretta. Un caso invece tristemente famoso di underfitting (o comunque data bias) riguarda l’algoritmo di riconoscimento immagini promosso da Google, il quale classificava volti di afro-americani come gorilla.
Si evidenzia anche come quindi un elevato numero di esempi riduca la probabilità che un esempio anomalo influisca eccessivamente sull’output dell’algoritmo.
Vastità e composizione del training set: la predisposizione di un corretto set di training è fondamentale per computare un processo di apprendimento automatico, ma la domanda immediatamente successiva è: cosa significa “corretto”? Di quanti dati abbiamo bisogno? La risposta non può essere univoca e dipende ad esempio dalla vastità del problema che vogliamo risolvere e dalla complessità dell’algoritmo di apprendimento.
Un buon approccio potrebbe essere:
- Analogia: quali problemi analoghi a quello che stiamo affrontando sono stati risolti in precedenza, e con quale set di dati?
- Esperienza: quanto sono esperto del dataset che sto andando ad utilizzare per il mio modello? Quanto ne conosco casi specifici, complessità, e trabocchetti? Quanto è sporco il dato che conto di adoperare? Semplificando al massimo, supponiamo di dover classificare i testi di canzoni in base al loro genere; quanti testi di canzoni hip-hop e quanti testi di canzoni rock devo leggere prima di trovare un pattern che ne permetta la classificazione? Questo numero sarà vicino al set di dati che devo fornire al mio algoritmo per la fase di apprendimento, facendo le dovute proporzioni. La conoscenza del campo di applicazione diventa, in altri termini, discriminante.
- Euristica: schematizziamo il nostro set di dati e facciamo in modo che ci sia un congruo numero di classi indipendenti, che ci sia un congruo numero di falsi negativi, che siano rappresentati i casi limite di complessità ragionevolmente stimabile.
- Nel dubbio: Get More Data. Il machine learning è un processo induttivo, il modello può catturare solo quello che ha già visto. Quindi una lacuna nel modello potrebbe comportare un output fallato da parte del nostro algoritmo. Tralasciamo per semplicità qui il tema della pulizia del dato che meriterebbe un libro a parte.

Ecco infine il mio codice head-to-toe se volete provare un run ignorante sul vostro IDE:
7. Log out
Anche la scienza è popolare: questo testo è stato possibile grazie a numerosi confronti e sessioni condivise con un team di data scientist ed esperti di Python (che si sono anche assicurati della bontà delle affermazioni fatte – sebbene ogni errore sia imputabile alla mia negligenza).
Volete condividere il vostro punto di vista o la vostra esperienza a riguardo dell’applicazione di tecniche di Machine Learning con Python o case study interessanti? Scriveteci!

Scarica l’ebook “La guida definitiva alla comprensione del Debito Tecnico”
Iscriviti alla newsletter e scarica l’ebook.
Ricevi aggiornamenti, tips e approfondimenti su tecnologia, innovazione e imprenditoria.


